Desktop PCの起動時にファンが数秒毎に回る/止まるを繰り返す
タイトルのような状態になりpcが起動しなくなった。最終的に電源の交換により復旧したので調べたことをメモ。
問題発生
まず、上記のように起動しなくなる数ヶ月前からなんでもないところで突然再起動するという症状がたまに出ていた。そしてタイトルのような症状になったのだが、一回目は以下のようなブログを参考にしつつチェックを行い、メモリを一度付け直してしばらく電源コードを抜いた状態で置いてところ復旧した。
#001 電源を入れるとファンが一瞬回転→停止→回転を繰り返す |★PC修理ブログ
【解決】自作パソコンが短く再起動を繰り返す、BIOS前の一瞬 | プロガジ
自作PCの電源を入れたら一瞬ついて消えるときの7つの対処法 – にゃんさー
しかし、そのまま1ヶ月ほど経ったくらいで同じ症状が再発し今度は同じ方法では復旧しなかった。
ちなみに発生した環境は以下
- OMEN30L with 3090
- windows11
- 購入してから1年半程度が経過
以下のような理由からなんとなく電源の問題ではないかと思っていた
- 一度は同じ症状から復旧した(この際cpu, gpuはいじってない)
- 今回はメモリを付け直しも復旧せず
- 以前から突然の再起動がたまに発生していた
また、OMEN30Lで調べていると要求の割に電源のスペックが低いのでは?という話があるらしい。一応今回のケースだと、厳密には計算してないが要求は最大でだいたい600~650W程度、載っている電源は750W。
違ってたら残念ではあるものの、pcを開けてのパーツ交換は初めてなので勉強になりそうということで電源の交換をしてみることにした。
調査
まずは電源交換のための情報収集
- スペック
- OMEN30Lのレビュー記事
- 各パーツの交換手順動画(公式)
- OMENの電源交換に関するブログ記事
- ↑の人が載っけてくれてた電源交換の動画
特に公式で様々なパーツの交換手順解説動画が上がっているのは助かった。今回やりたいことに直結する電源交換に関する記事と動画も発見。
OMEN30Lはコンパクトなタイプであるのと、既存電源の奥行きに合わせた位置にロックするためのちょっとした出っ張りが付いている(↑の電源交換の動画でも言及されていた)ということでそれに合わせて155mm以下の電源を探す。
また、いろいろ調べているとやはり要求より大きい目の余裕のあるものにしておくと電源効率がよい・故障しづらい・静音性あがるなど書かれているので850 or 1000Wで探すことにした。
今までの用途だと機械学習の実験のためちょっとした学習(数時間程度)を回すくらいだったが、長時間動かす場合は常に大きな電力を使い続けることになるのも考慮。
スペックや値段、いろんな人が書いてくれてるレビュー記事を見つつ調査。1000Wで155mm以下のものはそれほどなく850Wにしようかと思っていたところ以下の電源を見つけた。
「NZXT C1000 Gold (2022)」をレビュー。抜群の静音性が魅力なスタンダード電源ユニット : 自作とゲームと趣味の日々
サイズをクリアしつつ1000Wで価格は2万弱(black friday sale)だったためこれにしてみた。
電源交換
電源交換の動画を参考にしつつ作業を進める。↑に貼った公式動画でケースの開け方や各種ケーブルの外し方は解説されておりその通りで問題なくいけた。また、初めてだったので一個ずつケーブルを確認しつつ進めているもう一つの動画も助かった。
いくつか引っかかった問題についてメモしておく
ケーブルが太すぎる
今回買った電源のケーブルはこちらのようにプラグから数cm分以外は束ねられている。

OMEN30Lに元から載っている電源はこちらのようにケーブルは完全に束ねられているわけではない
純正新品 HP OMEN Obelisk 用 Cooler Master Lite-on製 DPS-750AB-40D 750W 対応24-Pin電源ユニット ATX Power Supply L84096-003 80PLUS Platinum :Gmk-DPS-750AB-40D:Melville - 通販 - Yahoo!ショッピング
これは裏側の配線用のスペースの厚みが数cmしかないためで、ちょっとバラけた状態になることで比較的平らにして通すようにされていた。
一応まずは元と同じように繋げてケースを閉めてみたものの案の定まったく閉まらないため、しばらく考えたが以下のように乗り切った。
- cpuケーブルは束ねている網目上のカバーを剥がす
- 剥がすことは想定されておらず結構しっかりと止められていたが、端をハサミで切ってから手で破くことでバラせた
- それ以外のケーブルはケース内を通す
- HDDはデフォルトで一つだけしか載っておらずまだ使っていない状態であったため、HDD一個分の空き部分を通すことでケース内で配線できた
cpuケーブルも中を通すことも考えたが、長さ的に足りず外を通さざるを得なかった。外を通せるならその方がスッキリするのでよいというのもある。
逆に他のケーブルも全部剥がして外を通すこともできるはずだが、cpuケーブルを剥がした段階で結構な力を使い疲れたので中を通した。ちゃんと工具を持っていて無理なく切れるなら全部キレイにはがして外を通すのが良さそう。
また、次に書いたようにHDD用の延長ケーブルは買ったので、一緒に他のもコンパクトな延長ケーブルを買ってしまった方がベターな気はするが、ひとまずできたので今回はこれで。
HDDケーブルのプラグ部分がL字じゃないとダメ
元のHDD用電源ケーブルのプラグはL字だったのだが、今回買ったものは真っ直ぐのものが付属されていた。OMEN30LのHDDの差し込み口とケースのパネルとの間は数cmしか余裕がなく、真っ直ぐなものだとプラグ部分の長さだけで既にはみ出す状態に。
これはこのままじゃ解決しようがないのでL字の延長コードを購入して解決。
起動チェック
既にHDDケーブルの購入について書いてしまったが、実際はこの時点ではHDDは必要なかったため(systemはssdなので)マザーボード、cpuだけ繋いで起動チェック。
無反応
しかし全く反応せず。そもそもファンが回っていない状態。
ケーブルを繋げる途中でマザーボードへのプラグ差し込みが気持ちよくカチッといってなかったので、ちょっと調べてみるとケーブルによってはうまくはまりづらい場合もあるとのこと。なので少し無理やり力を込めて押し込んでみた。
これで起動したところファンは回って一応起動した。
ブザーが鳴る
ただ、すぐにブザーがなって落ちた。ブザーの鳴り方で調べてみるとgpuっぽい
【解決】自作パソコンが短く再起動を繰り返す、BIOS前の一瞬 | プロガジ
というのも当たり前で、gpuのケーブルは繋いでなかった。ディスプレイへの出力のためにgpuは必要だった。
なのでgpuも繋いで再度起動してみたところ、無事OSのログインまで完了することができた。
まとめ
ということで、最終的な結論として電源の故障だったことが確定。まだ1年半程度しか経っていなかったのでちょっと残念だが、電源の交換を行えたことは勉強になったし、結果的にアップグレードできたのでよかったということで完了。
あとは新しい電源の耐久性の問題だがこれは時間が経たないとわからないため様子見。
実際のところ、今回選んだ電源は有名どころの安定電源ではなく、条件を満たしているわりに安めに手に入ったという感じなので万一の場合は仕方ない。これですぐ壊れた場合は次回はちゃんと多めにお金をかけて買おうと思う。
一枚の画像に映る人物に対するSMPL上での部分的なtexture mapを取り出す
denseposeとsmplの組み合わせはよく見かけるので勉強がてら一つやってみる。
実装も上がっており、やっていることも最小限に見えるのでこちらの論文の前処理を題材とする。
やりたいことは、一枚の画像に映る人物をSMPLのtexture mapとして取り出すこと。
ちなみにSMPLについては以前記事を書いた
https://jsapachehtml.hatenablog.com/entry/2023/10/29/200455
人物領域の推定にはdenseposeを利用する
- http://densepose.org/
- image上の人物領域における各pixelについて以下を推定するモデル
- どのパーツに属するか
- そのパーツ上でどの位置にあるか
- 様々な姿勢の人物画像とそのSMPL mesh上での対応点のペアを学習データとしている
パーツ分けについては位置の回帰がしやすいよう独自の分け方をしており、SMPLの元のtexture mapとは異なるが、同じmeshを参照してるものなので相互に変換できる。
denseposeでのIUV map作成
こちらの画像をサンプルとして使う
https://github.com/thmoa/tex2shape/blob/303b94f/data/images/spotlight_001.jpg
{kind=link}
denseposeは論文が出た時点と実装の管理方法が変わっていて、現在はdetectron2の一部として統合されていた。
- 元のrepo: https://github.com/facebookresearch/DensePose
- 今のrepo: https://github.com/facebookresearch/detectron2/tree/main/projects/DensePose
新しい方のrepoの実装を利用する。
論文にあるこちらの画像右のtexture map形式の画像を得ることが今回の目的であり、そのためにまず真ん中のようなIUV mapを得たい 。

denseposeの推論にはこちらのスクリプトが用意されており、入力画像に対する推論結果が画像化できる
https://github.com/facebookresearch/detectron2/blob/main/projects/DensePose/doc/TOOL_APPLY_NET.md#visualization-mode
ただ、入力画像に推論結果のmaskを重ねて表示するもののようで、IUV map自体の画像を出力してくれるオプションはなかった。中を見てみると例えばこのようにIUVを利用してる部分がある。
https://github.com/facebookresearch/detectron2/blob/4e80df1/projects/DensePose/densepose/vis/densepose_results_textures.py#L51
なのでこれだけ出力するよう簡易なオプションを実装して使った。
https://github.com/y-kamiya/detectron2/commit/c44db8b3e146fa6ac89825645492f2278a1b8425
apply_net.pyのドキュメントを参考に以下のコマンドでIUV mapを出力
python apply_net.py show configs/densepose_rcnn_R_50_FPN_DL_s1x.yaml R_50_FPN_DL_s1x.pkl spotlight_001.jpg dp_iuv_map --output spotlight_001.png -v
これで左ような画像(=spotlight_001.0001.png)が取得できる(右は入力画像)

ちなみに環境構築に関してはこちらに書いてある通りで、python3.10系、torch==2.1.0でも問題なく動いた
https://github.com/facebookresearch/detectron2/blob/4e80df1/projects/DensePose/doc/GETTING_STARTED.md#installation-as-a-package
学習済みモデルについてはこちらから精度の高いものを選んで落とした
https://github.com/facebookresearch/detectron2/blob/4e80df1/projects/DensePose/doc/DENSEPOSE_IUV.md#-model-zoo-and-baselines
texture mapの作成
densepose用のformatからSMPLのformatへの変換部分について、論文著者が効率のためlookup tableを事前に用意したと書いてあり今回はそれを利用する
For easier mapping, we precompute a look-up table to convert from 24 DensePose UV maps to the single joint SMPL UV parameterization.
変換を行っているのはこちらの処理
https://github.com/thmoa/tex2shape/blob/504c69ee4a08f6e6ed42460645acd301f7fc680d/lib/maps.py#L6
入力画像の各pixel値をIUV mapが示すtexture map上の位置へコピーしている
この関数を使うように以下の簡易なスクリプト(=unwrap.py)を実装
import cv2
import os
import argparse
import numpy as np
from lib.maps import map_densepose_to_tex
def main(img_file, iuv_file):
img = cv2.imread(img_file) / 255.
iuv_img = cv2.imread(iuv_file)
unwrap = (map_densepose_to_tex(img, iuv_img, 512) * 255).astype(np.int32)
out_file = os.path.basename(img_file)
cv2.imwrite(f"out/unwrap_{out_file}", unwrap)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('image', type=str, help="Input image")
parser.add_argument('iuv', type=str, help="Densepose IUV image")
args = parser.parse_args()
print(args)
main(args.image, args.iuv)
実行
python unwrap.py spotlight_001.jpg spotlight_001.0001.png
出力
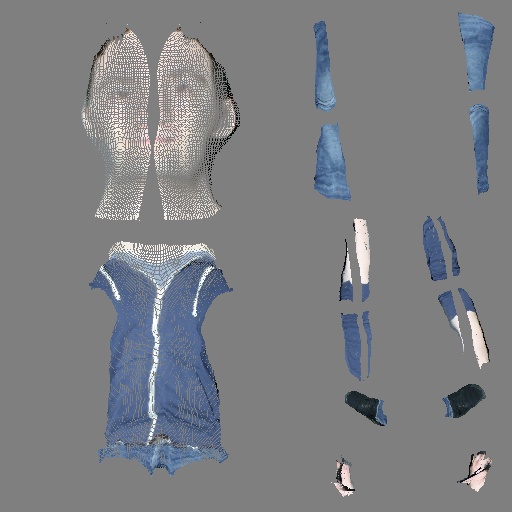
だいぶスカスカのtexture mapになるが、正面から見た一枚のみから抽出した部分的なものなのでこうなる。
ちなみに論文だと、これを入力としてpix2pixの形式でnormal mapとdisplacement mapを予測するよう学習し、入力画像の3d形状を推定している。
pytorch3dのTextureUVでSMPLのmeshにtextureを貼る
3dの人体形状モデルとして有名なものにSMPLというのがあり、形状(shape)と姿勢(pose)を指定することで様々な人体形状のmeshを作り出せる。
https://smpl.is.tue.mpg.de/
SMPL自体はmeshを生成するものだが、対応するtexture mapも配布されていて、3d生成関連の論文読んでいるとよく使われているのを見かける。なので勉強がてらpytorch3dを使ってSMPLのmodelにtextureを貼ってみたのでメモ。
pytorch3dのinstall
手順はこちらに従う
https://github.com/facebookresearch/pytorch3d/blob/28f914b/INSTALL.md
mac環境なのでcudaは気にせずpipで入れた
pip install torch==1.13.0 torchvision MACOSX_DEPLOYMENT_TARGET=10.14 CC=clang CXX=clang++ pip install "git+https://github.com/facebookresearch/pytorch3d.git@stable"
2.0系だとビルド時にエラーが出たので1.13.0を使っておいた。pytorch3dのinstall時点でpytorchが入ってないと依存でエラーになるので先にpytorchだけ入れておく。
ちなみにエラー内容としてはc+17が有効になってないというものだった。私の環境ではclang 14.0が入っていてc+17がデフォルトになってないversionだったためと思われる。
https://cpprefjp.github.io/implementation.html#clang
clang 16.0以降を使う、またはビルド時にc+17を使うようフラグを渡せばpytorch2系でもOKなはずだが目的から外れるのでとりあえずこのまま。
SMPLの準備
python環境かつuv座標の情報が必要なので SMPL for Python Users > Download UV map in OBJ format からダウンロードする。ちなみに取得にはメアドでのユーザ登録が必要。
https://smpl.is.tue.mpg.de/download.php
zipを開くとobjファイルと一緒にtexture mapのサンプルも入ってるのでこれを使うことにする。

pytorch3dによる描画
denseposeのtextureをSMPLに貼り付けるチュートリアルがあるのでこれと同じ形でOK
https://pytorch3d.org/tutorials/render_densepose
densepose -> smplへのuv map変換処理を除いて単純にTexture, Meshを作ればよいはず
with Image.open(tex_path) as image:
np_image = np.asarray(image.convert("RGB")).astype(np.float32)
tex = torch.from_numpy(np_image / 255.)[None].to(device)
verts, faces, aux = load_obj(obj_path)
texture = renderer.TexturesUV(maps=tex, faces_uvs=[faces.verts_idx], verts_uvs=[aux.verts_uvs])
mesh = Meshes([verts], [faces.verts_idx], texture)
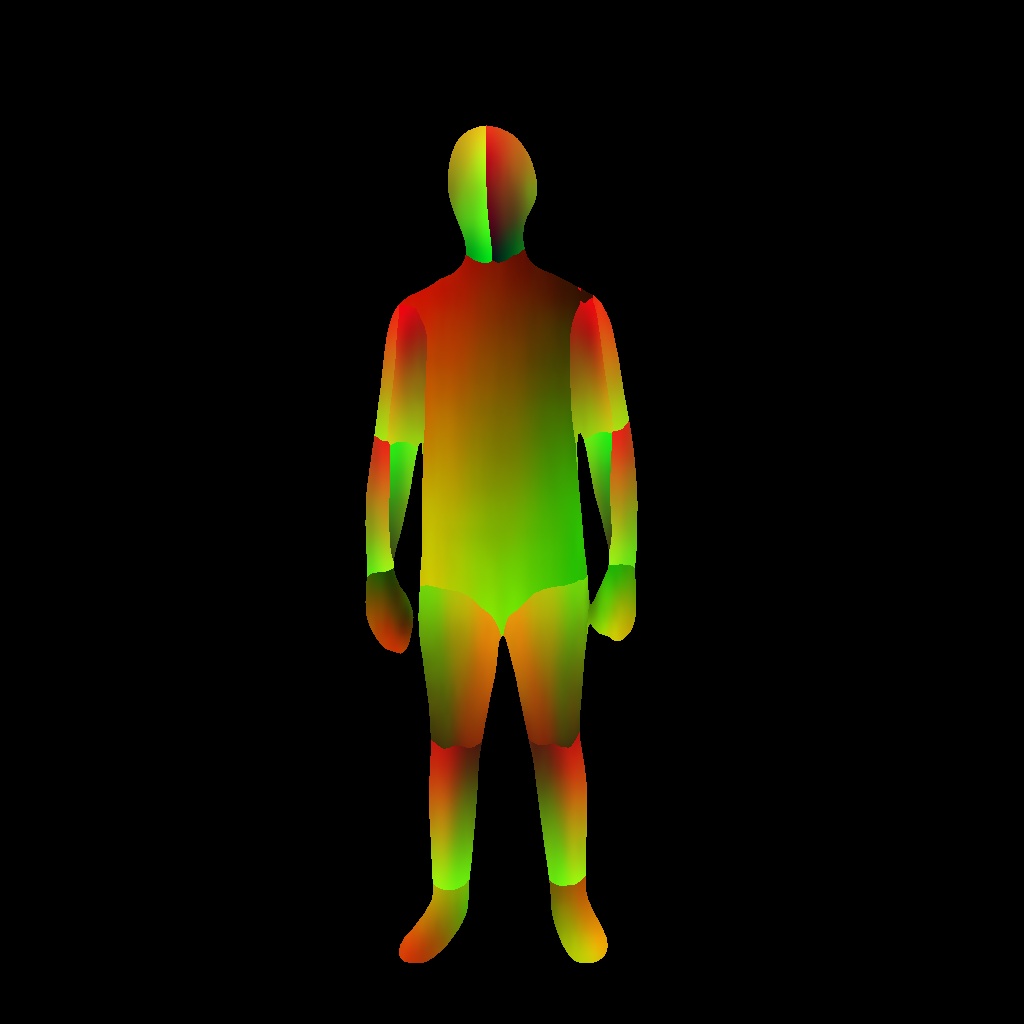
ということで描画してみるとこうなる
 網目が完全に崩れているので何かおかしい
網目が完全に崩れているので何かおかしい
TextureUVの定義はこれ
https://github.com/facebookresearch/pytorch3d/blob/297020a4b1d7492190cb4a909cafbd2c81a12cb5/pytorch3d/renderer/mesh/textures.py#L612
と書いてあるので良さそうに思える。
実際に渡しているデータを調べてみるとvertsとverts_uvsのデータ数が合っていない
verts, faces, aux = load_obj(obj_path) print(verts.shape) # torch.Size([6890, 3]) print(aux.verts_uvs) # torch.Size([7576, 2])
SMPLのmeshの頂点数は6890個なのでverts_uvsのデータ数がそれより多くなっている模様。facesのデータを見てみるとこう
verts, faces, aux = load_obj(obj_path) print(faces.verts_idx.shape) # torch.Size([13776, 3]) print(torch.max(faces.verts_idx)) # tensor(6889) print(faces.textures_idx.shape) # torch.Size([13776, 3]) print(torch.max(faces.textures_idx)) # tensor(7575)
faces.textures_idxがaux.verts_uvsのindexと対応しているということだった。
見る方向による色の違いを表現するため、mesh頂点毎にuv座標を指定するのではなく、同じ頂点でも別のfaceの場合は異なるuv座標が対応するとのこと
https://github.com/pmh47/dirt/issues/46#issuecomment-540392773
TextureUVの引数を修正して
texture = renderer.TexturesUV(maps=tex, faces_uvs=[faces.textures_idx], verts_uvs=[aux.verts_uvs])
とすることでちゃんと網目の模様になった

import os
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from pytorch3d.structures import Meshes
import pytorch3d.renderer as renderer
from pytorch3d.io import load_obj
device = torch.device("cpu")
def create_renderer():
R, T = renderer.look_at_view_transform(1.0, 0, 0)
cameras = renderer.FoVPerspectiveCameras(device=device, R=R, T=T)
raster_settings = renderer.RasterizationSettings(
image_size=512,
blur_radius=0.0,
faces_per_pixel=1,
)
lights = renderer.PointLights(device=device, location=[[0.0, 0.0, 2.0]])
return renderer.MeshRenderer(
rasterizer=renderer.MeshRasterizer(
cameras=cameras,
raster_settings=raster_settings
),
shader=renderer.SoftPhongShader(
device=device,
cameras=cameras,
lights=lights
)
)
# downloadしたSMPLのzipを展開してこのpathに置いておく
DATA_DIR = "./data"
tex_path = os.path.join(DATA_DIR, "smpl/smpl_uv_20200910.png")
obj_path = os.path.join(DATA_DIR, "smpl/smpl_uv.obj")
with Image.open(tex_path) as image:
np_image = np.asarray(image.convert("RGB")).astype(np.float32)
tex = torch.from_numpy(np_image / 255.)[None].to(device)
verts, faces, aux = load_obj(obj_path)
texture = renderer.TexturesUV(maps=tex, faces_uvs=[faces.verts_idx], verts_uvs=[aux.verts_uvs])
mesh = Meshes([verts], [faces.verts_idx], texture)
renderer = create_renderer()
images = renderer(mesh)
plt.figure(figsize=(10, 10))
plt.imshow(images[0, ..., :3].cpu().numpy())
plt.axis("off");
plt.show()