以前copy taskまで実装したものについてまとめた
transformerを理解するために実装 - MEMOcho-
今回はそれを実際のデータで学習するところを実装したのでメモ
目次
sentenceのtoken化
自然言語の文をニューラルネットワークで扱うためにはまず各ワードをid化するなどの処理が必要がある。 しかし、ただ単にワード毎に数字をふるだけではtoken数が膨大になってしまい以下のような問題がある
- メモリに乗り切らないため一定以上のサイズは計算不能
- データ上にあまり出てこないワードは正しく学習できない
- 当然まったく学習データに出てこない未知語も存在する
これを解決するのがサブワード分割という手法であり、高頻度なワードはそのままに、低頻度はワードはさらに小さい単位に分割してtoken化するというもの。 代表的なものとしてよく使われるのがByte Pair Encoding(BPE)というもので、事前に指定したtoken数になるまで分割していく。
これによって未知語がなくなり(文字単位まで分割してしまうのなら)かつtoken数も膨大にならずバランスの取れた状態を作れる。 ただし日本語などの単語境界が自明でない言語の場合、その前にmecabなどによって形態素解析を行い単語分割する必要があるがその分割方法も精度に影響する。
このあたりをできるだけ手間をかけずに行うために今回はsentencepieceを使う。
sentencepieceは文全体をデータとして与えることで単語分割部分も含めて計算してくれ、分割方法も使うデータに最適化されたものとなる。 (逆にいえばtrainデータ上の出現頻度の偏りが分割に影響するため、testデータと大きく異なる場合は精度が出ない)
作者が書いたqiitaがあるため詳細はこちらへ
Sentencepiece : ニューラル言語処理向けトークナイザ - Qiita
使い方はこんな感じ
cat train.orig.ja train.orig.en > spm_input spm_train --input=spm_input --model_prefix=test --vocab_size=8000 --pad_id=3 cat train.orig.ja | spm_encode --model=test.model --output_format=id > train.ja cat train.orig.en | spm_encode --model=test.model --output_format=id > train.en
実装したモデルではpadding用のid=3としているため、それに合わせるため--pad_id=3を渡す。 spm_trainによって生成されたtest.modelをencode時に使ってtokenをid化する。
ちなみに両言語をあわせて一つのvocabularyとする形をとったが、これはtransformerではなくXLMで導入された改善ポイントである。 本来のtransformerの場合はそれぞれの言語で別のvocabularyとしていたようなので注意。
長過ぎる文を削除
一文あたりのtoken数が多すぎると処理中にpaddingが多くなって無駄が多いだけでなく、メモリに乗り切らなくなって計算できない。 なのであまりにもtoken数が多い文は除く。
今回は簡単のためデータセット作成の段階で処理した
ちなみにXLMだと学習開始時のdatasetロード時に処理していた。また、他にも最適化を入れていて勉強になったのでメモしておく。
- 1 batchに含まれる最大token数の文に合わせてtensorのサイズを変える
- これによりpadding tokenが少なくなり無駄が減る
- https://github.com/facebookresearch/XLM/blob/9e6f6814d17be4fe5b15f2e6c43eb2b2d76daeb4/src/data/dataset.py#L115
- datasetをsentenceの長さ順にsortする
- 同程度の長さのsentenceが一つのmini batchになることでpadding tokenが減る
- https://github.com/facebookresearch/XLM/blob/9e6f6814d17be4fe5b15f2e6c43eb2b2d76daeb4/src/data/dataset.py#L217
- 1 stepで処理するtoken数が毎回同程度になるようにmini batch内のsentence数を変える
- これによりtoken数が例外的に多いsentenceが存在したとしてもメモリに乗り切らないという自体を回避できる
- https://github.com/facebookresearch/XLM/blob/9e6f6814d17be4fe5b15f2e6c43eb2b2d76daeb4/src/data/dataset.py#L223,L227
fp16対応
XLMの実装を参考にこれを使った
去年みたときに比べてインターフェースがシンプルになったようで、モデルの初期化時にampによる初期化を行うだけで後はうまいこと中で処理してくれる模様。 (以前は半精度にしたい部分にhalf()などのメソッドを明示的に呼んでおく必要があった)
この修正だけで対応できた
https://github.com/y-kamiya/transformer/pull/1/commits/ab8e0559a07912b12773fa3209dec41e4bd1a302
colabのP100で試してみたところ
- fp32だとbatch_size=512でout of memoryでエラーになるが、fp16だと学習可能
- メモリ消費削減を確認
- fp32: 11300 tokens/sec、fp16: 11900 tokens/sec
- 若干スループットが向上?
P100の場合、fp16とfp32で単純に2倍分のスループットの違いがあると思われるが、fp16を有効にしても秒間の処理token数はそこまで変化しなかった。
colabのT4で試したところ
- fp32: 7100 tokens/sec、fp16: 15500 tokens/sec
こちらは2倍以上の向上につながった。tensor coreが搭載されており、fp16とfp32のスペック上の違いは8倍程度あるはずなのでそれに比べると小さな効果に見える。
おそらくbatch_sizeを大きくするなどして1度に処理されるデータ量を大きくすることや、より複雑なモデルでgpuによる処理の割合が大きなればより効果が出るようになると考えられる。
参考
PyTorch + ApexでMixed-Precision Training - Qiita
FP16 in Pytorch. The Turing lineup of Nvidia GPU’s has… | by Dwight Foster | Medium
colabでの学習
接続毎にGPUの種類が変わるため処理にかかる時間が毎回変わるのに注意。そのとき何を使っているか毎回確認しておくとよい。 各gpuのスペック比較はこちらを参考にさせてもらった
種類によっては半精度浮動小数点数に対応していないものもあるので注意
また、colabの場合は途中で切れてしまったりということが起きるため、outputの出力先はdriveにしておいた方がよい。 colabでやることが前提だったこともあり、今回の実装ではepoch数なども出力ファイルに保存することでそこから学習が再開できるようにした。
評価指標
これもXLMを参考に以下の3つを使った。
- perplexity
- 1 tokenあたりのlossのexponentialを取ったもの
- accuracy
- tokenの種類と位置についての参考訳(教師データ)との一致率
- BLEU
- 機械翻訳の精度評価によく使われる指標(人の評価と相関関係にあることがわかっている)
- モデルの評価 | AutoML Translation のドキュメント | Google Cloud
BLEUの計算にはnltkというライブラリを使った。
実行結果
やっていることは
- sentencepieceのモデル生成
- 生成したモデルによるid化
- BOS, EOS tokenの付与
- 空のsentenceと長すぎるsentenceの削除
ここで生成されたtrain.enなどのファイルがtransformer.pyで使う入力データとなる
seq2seq tutorial
pytorchのseq2seqチュートリアルで使われているデータで試してみたもの。
両言語それぞれ1100件程度だったので、1000件をtrain、100件をvalid用にし、vocabulary sizeは1000とした(適当に決めた)
実行したときのコマンド
!python transformer.py --dataroot data/seq2seq-tutorial --src en --tgt fr --n_words 17 --vocab_size 1000 --epochs 300 --epochs_by_eval 10 --batch_size 128 --dim 32 --log_interval 100 --name dim128_batch32
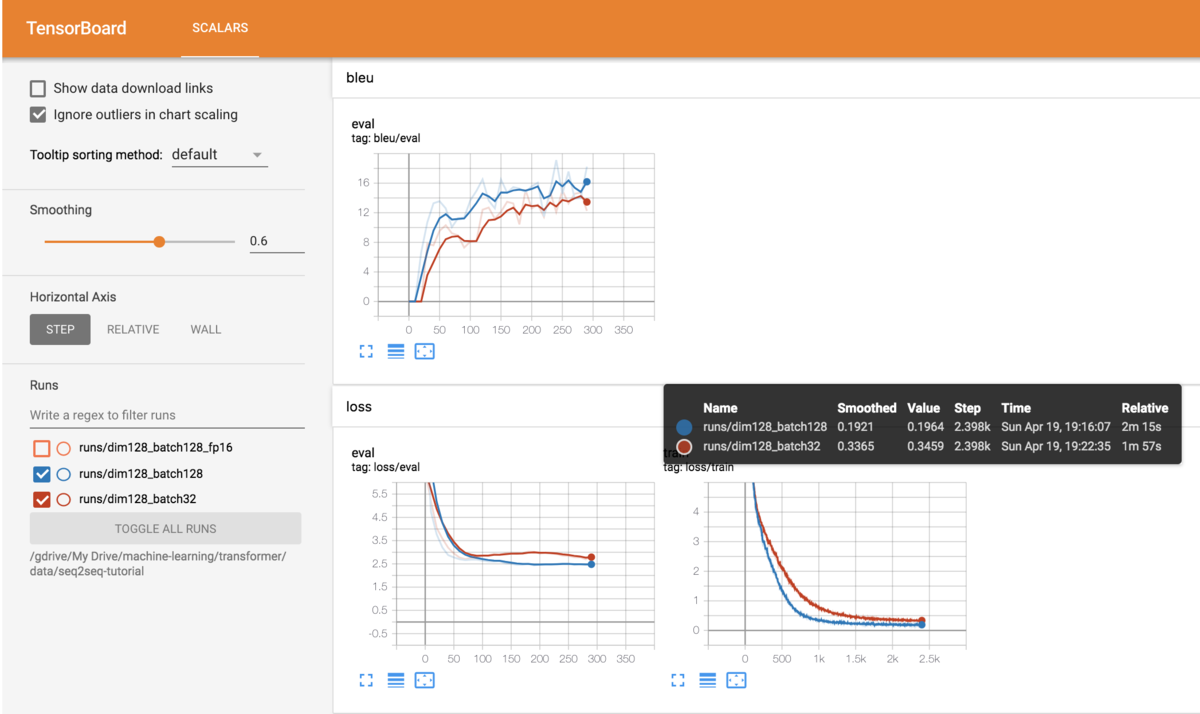
数分でこの状態になるのでデバッグに使える
IWSLT2015
このデータセットを使った理由は大きすぎないことと、公式実装でも評価結果が出ているようで参考になる指標が出ていること (ただし、今回は評価用のデータからも長いsentenceを削除してたりするため比較はできない)
IWSLT2015 English-German Benchmark (Machine Translation) | Papers With Code
データはこちらのスクリプトで取得
処理後のデータ数はこれくらいだった
- train: 160K
- valid: 2K
- test: 7K
colab上で学習するのですばやく学習したい理由から、64tokenより多いsentenceはすべて取り除いてある。 (最大で700 tokensというsentenceも存在したため、そのままだとbatch_size=2とかで学習することになってしまう)
学習実行(gpuはP100)
!python transformer.py --dataroot data/iwslt2015 --src en --tgt de --dim 512 --vocab_size 8000 --n_words 64 --batch_size 128 --epochs 200 --log_interval 400 --epochs_by_eval 2 --name dim512_batch128_fp16 --fp16
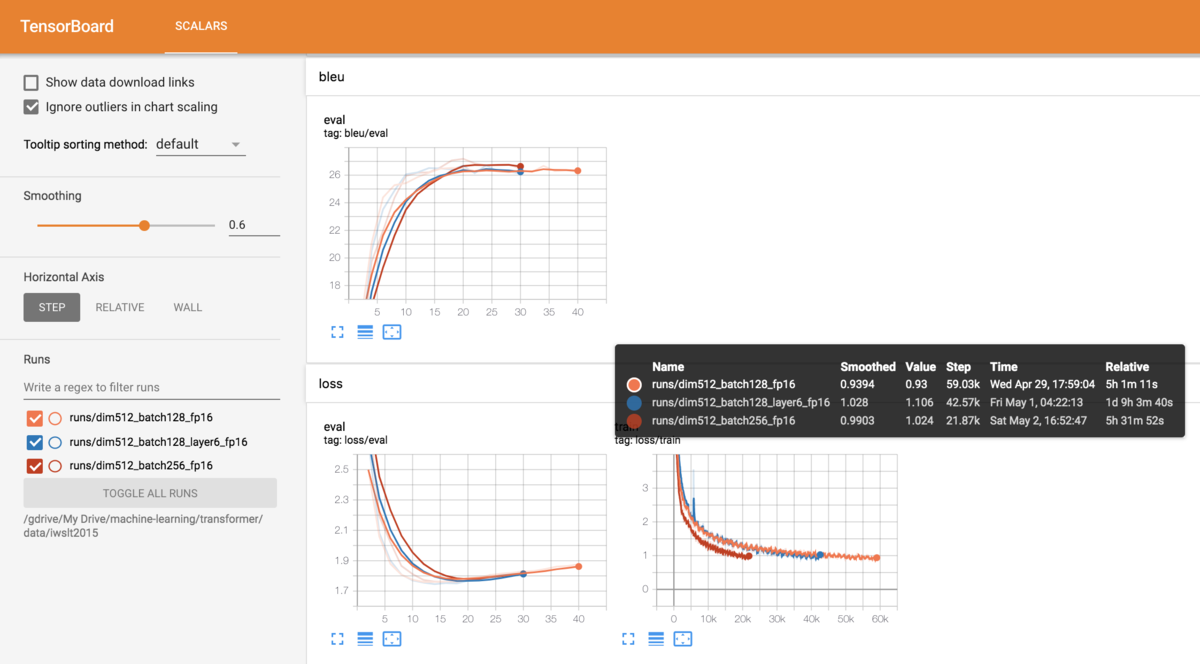 evalは横軸がepoch数であり、trainは横軸がstep数
evalは横軸がepoch数であり、trainは横軸がstep数
testデータのベストスコア
!python transformer.py --dataroot data/iwslt2015' --eval_only --src en --tgt de --name dim512_batch128_fp16 --fp16 ============================== data_type: valid ppl: 4.59 acc: 63.66 bleu: 31.15 ============================== ============================== data_type: test ppl: 3.36 acc: 70.54 bleu: 35.38 ==============================
評価データも64 tokens以下のものに絞ったためと思われるがたいぶ高いスコアになった。 今回の実験ではvalidもハイパーパラメータの調整などに使っていないため実質的にtestデータとして使えるのだが、せっかく用意したので元のtestデータでもスコアを出してみたところけっこう差が出た。
調べてみたところtestデータの方がsentenceあたりの平均token数が1少なかったがそれだけでここまで差が出るとは思えない。あと違いとしては元のデータセットに含まれるTEDXと付いたadditionalな対訳データも含めたことかもしれない。testデータの方がTEDXからくるデータの割合が少なかったため、trainデータと似たデータがvalidより多めに入っていた可能性。
kftt
京都議定書の文章を日英で人が翻訳したデータセット。やることは同じだが日本語でも試してみたいため使ってみた。 IWSLT2015より大きく、trainデータが440K程度ある。
データはこちらのスクリプトで取得
処理後のデータ数はこれくらいだった
- train: 370K
- valid: 1K
- test: 1K
datarootが異なるだけで学習・評価時の設定はIWSLTのときと同じ(gpuはT4)
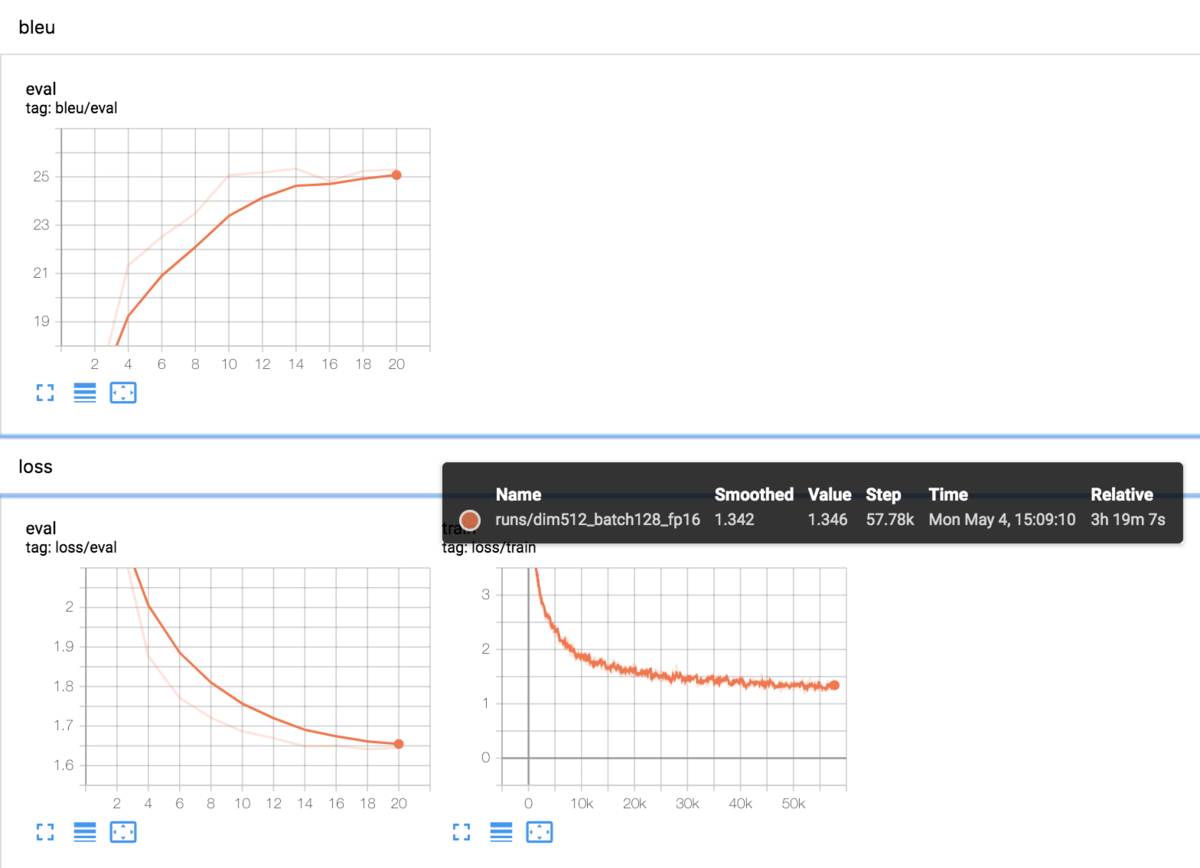
============================== data_type: valid ppl: 5.20 acc: 62.02 bleu: 25.34 ============================== ============================== data_type: test ppl: 4.23 acc: 66.05 bleu: 29.34 ==============================
こちらもtestデータの方がスコアがかなり高くなった。こちらは用意されていたデータそのままのはずであるため理由はよくわからない。こうなると一番あやしいのは私の評価用の実装がおかしいということか、、(testデータの方がtrainデータに近いものになっていたということもありうる?)
翻訳を試してみたのがこちら
1987年の国鉄分割民営化にともなってJR西日本が引き継いだ。 The JR West took over the line as a result of the division and privatization of JNR in 1987. 子供の頃はテニスをやっていた。 He was in the tennis when he was a child. 私は映画館に行きます。 I went to Movie Land. こんにちは、今日は天気がいいですね! Chihanachihayashi-imo-gaeshi-imo-gae-imo-gae-imo-gae-imo-gae-ide--ide--ide---ino-udon--i
一つ目はtestデータに含まれていたものそのままであり、学習データと同様のトピック・言いまわしであるため意味が通る文になっている。
ちなみにtestデータ中の参考訳はこちら
JR West Japan took over the facility in 1987, following the breakup and privatization of Japanese National Railways.
2つ目・3つ目は学習データにありそうな文を適当に考えて入れたもの。in the tennisや過去形になってるところがおかしいが、子供の頃などはちゃんと訳せている。
4つ目は会話系の文でおそらく学習データには含まれないと思うもの。おかしな文が出てくるとは思っていたが、想定よりもひどく文が完全に崩壊してしまったw
ということで、実際に使うものを作るためには使い所に合わせたデータを用意する必要があるというのがよくわかる。
参考
DeepLearningExamples/prepare-iwslt14.sh at master · NVIDIA/DeepLearningExamples · GitHub