google colaboratoryで効率よくデバッグしたい
google colaboratoryはgpuやtpuを無料で使うことができ大変便利だが、gpu関連の処理をデバッグしたい場合などは多少手間がかかる
colab上での実行が必須のコードのデバッグ時に私が行っていた手順は以下
- ローカルでコードを変更
- 適当にコミット
- colab上でgitコマンドによりコードを更新
- colab上で実行
3.の際は以下のようなコマンドを使っていた
!git reset --hard HEAD~3 !git pull !git log -n1
resetはコミットをまとめ直したとき用、logはちゃんと意図どおりに更新されたかの確認用
慣れてしまえば小さな手間なので気にしてなかったがちょっと調べてみたらもっとよいやり方を見つけたのでメモ
以下のどちらかを使うというのが答え
どちらのツールもローカルPCのファイルシステム経由でgoogle driveにアクセスできるようにするもの
各機能の比較はこちらがわかりやすかった
https://www.cloud-ace.jp/column/detail82/
これらはgoogle colaboratoryを使うか否かに関係なく、そもそもgoogle driveとのやり取りが効率よくできるようになるためdriveを使うなら入れておいた方がよい類のものだった
google-drive-file-stream
企業用のgoogleアカウントを持っている場合のみ使えるツールで基本的にgoogle-backup-and-syncより高機能
brew install google-drive-file-stream
google driveをローカルPC上にマウントする形のため、実際にローカルにあるファイルやディレクトリと同様の扱いで操作できるため作業効率がとても上がる
driveへのdownload, uploadはcliなら cp などで済むし当然finder経由でも操作できる
これ経由で冒頭にあったcolab上でのデバッグを行う場合、まず前提として
- ローカルPC上でマウントされたdriveの任意の場所にrepoをclone
- colab上でもgoogle driveをマウントしておく
デバッグする場合は
- ローカルPCで上記cloneしたrepoのコードを変更
- colab上でマウントしたdrive上のrepoのコードを実行
で済むため、pushしてpullしての部分がなくなる(=ローカルで実行する場合とまったく同じ手数でよくなる)
ただし、当然だがローカルPCでの変更をcolab上から読めるようになるまでに若干のラグがある(私の環境では数秒程度)
なので注意点としては
- colab上で実行する前に数秒待つ必要がある
git statusなどrepoの情報を集計する操作も数秒のラグが発生する- 参照が必要なファイルが多いほど時間がかかるようになることに注意
google-backup-and-sync
個人のアカウントでも利用可能なツールで任意のディレクトリをdriveとローカルで同期しておくことができる
brew install google-backup-and-sync
必要なrepoをdriveとローカルで同期する設定を入れておけば、file-streamで書いたことと同様のことが可能でデバッグの手間を削減できる。ただし、若干こちらの方が同期されるまでの時間が長いかも(10秒程度?)
そんなことありませんでした。意図せず複数ファイルが同期されていたから遅いように見えただけで1ファイルあたりの同期にかかる時間は体感として特に変わらず
テキスト感情分類(マルチラベル)
こちらの記事で追加でやってみると書いたことのいくつかについてやったのでメモ
https://jsapachehtml.hatenablog.com/entry/2021/01/17/142444
マルチラベル分類
参考にしたこちらの論文と同じ形にして精度を比べてみることにした(英語のデータセットで)
https://arxiv.org/abs/1812.01207
マルチラベル分類にするための修正はこちら
- lossの計算にbinary cross entropyを使う
- ラベル毎に0 or 1を出力したいため
- 評価用の出力をラベル毎にTrue/Falseの混同行列に変更
元のコードからの差分はこんな感じ
https://github.com/y-kamiya/emotion-classification/commit/e2f25685f9eedbba40db4a9bcecc5821ede3442f
細かい部分の修正は別コミットでもしているが大枠として
コードの全体はこちら
https://github.com/y-kamiya/emotion-classification/blob/feature/multi-labels/trainer.py
マルチラベル時とそうでない場合をオプションで変更して処理分けする形で実装してしまったのでちょっとわかりにくい。特にlabelsの扱いがマルチラベルの場合だけonehot表現になっているので注意
datasetの処理は特に汎用化せずSemEval2018 E-c専用。データ自体はこんなフォーマットになっている
ID Tweet anger anticipation disgust fear joy love optimism pessimism sadness surprise trust 2017-En-21441 “Worry is a down payment on a problem you may never have'. Joyce Meyer. #motivation #leadership #worry 0 1 0 0 0 0 1 0 0 0 1 2017-En-31535 Whatever you decide to do make sure it makes you #happy. 0 0 0 0 1 1 1 0 0 0 0 ...
メトリック修正
混同行列を表示する部分をマルチラベルの形に修正
def __log_confusion_matrix(self, all_preds, all_labels, epoch):
buf = io.BytesIO()
label_map = {value: key for key, value in self.config.dataset_class.label_index_map.items()}
np.set_printoptions(precision=3)
if self.config.multi_labels:
fig, axes = plt.subplots(1, len(label_map.keys()), figsize=(25, 5))
cm = metrics.multilabel_confusion_matrix(y_pred=all_preds.numpy(), y_true=all_labels.numpy())
for i in range(len(label_map.keys())):
# 表示を慣れた形にするため軸を入れ替え
mat = np.array([[cm[i][1][1], cm[i][1][0]], [cm[i][0][1], cm[i][0][0]]])
result = mat / mat.sum(axis=1, keepdims=True)
print(f'{label_map[i]}\n{result}\n')
display = metrics.ConfusionMatrixDisplay(result, display_labels=['P', 'N'])
display.plot(ax=axes[i], cmap=plt.cm.Blues, values_format='.2f')
display.ax_.set_title(label_map[i])
display.ax_.set_ylabel('True label' if i == 0 else '')
display.ax_.set_yticklabels(['P', 'N'] if i == 0 else [])
display.im_.colorbar.remove()
plt.subplots_adjust(wspace=0.1, hspace=0.1)
fig.colorbar(display.im_, ax=axes)
plt.savefig(buf, format="png", dpi=180)
scikit learnにはマルチラベル用の混同行列を計算するメソッドが用意されている
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.multilabel_confusion_matrix.html
各ラベルに対して2x2の混同行列を出力する形だが、True Positiveが右下となっておりよく見る形とは反転しているため、こちらで書かれているような形に修正して表示した
https://aidemy.net/courses/2010/exercises/Sy2YnLsLeG#:~:text=%E6%B7%B7%E5%90%8C%E8%A1%8C%E5%88%97%E3%81%A8%E3%81%AF%E3%80%81%E5%90%84,%E3%82%92%E3%81%BE%E3%81%A8%E3%82%81%E3%81%9F%E8%A1%A8%E3%81%A7%E3%81%99%E3%80%82
分類用headのカスタマイズ
論文に合わせて分類用のheadを変更した
class CustomClassificationHead(nn.Module):
def __init__(self, config, input_dim):
super().__init__()
self.config = config
self.fc1 = nn.Linear(input_dim, 4096)
self.fc2 = nn.Linear(4096, 2048)
self.fc3 = nn.Linear(2048, 1024)
self.fc4 = nn.Linear(1024, config.n_labels)
self.dropout = nn.Dropout(p=0.3)
self.prelu1 = nn.PReLU()
self.prelu2 = nn.PReLU()
self.prelu3 = nn.PReLU()
nn.init.kaiming_normal_(self.fc1.weight)
nn.init.kaiming_normal_(self.fc2.weight)
nn.init.kaiming_normal_(self.fc3.weight)
nn.init.kaiming_normal_(self.fc4.weight)
def forward(self, x):
# dropout is applied before this method is called
# https://github.com/huggingface/transformers/blob/v4.1.1/src/transformers/models/bert/modeling_bert.py#L1380
x = self.prelu1(self.fc1(x))
x = self.prelu2(self.fc2(self.dropout(x)))
x = self.prelu3(self.fc3(self.dropout(x)))
return self.fc4(self.dropout(x))
論文ではこのように書かれている
MLP(4096 → 2048 → 1024 → nc) with PReLU and 0.3 dropout
BertForSequenceClassificationはマルチクラス分類のときと同様に使い、classifierだけ上書きすることで簡単に変更できた
https://github.com/y-kamiya/emotion-classification/blob/232b09bf994148de987ab65346ddf699668187e1/trainer.py#L175
ちなみにBertForSequenceClassificationはこうなっている
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
def forward(...):
...
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
...
BertModelにdropoutを適用したものがclassifierの入力となっているため、CustomClassificationHead側では最初にdropoutを含めないようにした。重みの初期化も入れとく必要があるので注意。
また、学習率のwarmupも行っていたのでそれも入れた
self.warmup_scheduler = optim.lr_scheduler.LambdaLR(self.optimizer, lr_lambda=lambda step: min(1.0, (step + 1) / config.warmup_steps))
1×10−5 (constant after 1/2 epoch linear warmup)
実験
semeval2018 E-cデータセットをそのまま使って学習・評価を行った。前回と同じくgoogle colabを利用。
実行コマンド
!python trainer.py --dataroot "$DATAROOT/semeval2018" --lang 'en' --batch_size 96 --epochs 50 --log_interval 36 --eval_interval 2 --fp16 --lr 1e-5 --name lr1e-5_warmup_customhead --dataset_class_name SemEval2018EmotionDataset --no_save --warmup_steps 36 --custom_head !python trainer.py --dataroot "$DATAROOT/semeval2018" --lang 'en' --batch_size 96 --epochs 50 --log_interval 36 --eval_interval 2 --fp16 --lr 1e-5 --name lr1e-5_customhead --dataset_class_name SemEval2018EmotionDataset --no_save --custom_head !python trainer.py --dataroot "$DATAROOT/semeval2018" --lang 'en' --batch_size 96 --epochs 50 --log_interval 36 --eval_interval 2 --fp16 --lr 1e-5 --name lr1e-5 --dataset_class_name SemEval2018EmotionDataset --no_save
論文とは関係ない部分だが、どのくらい違いあるのか気になったので--custom_headの有無、--warmup_stepsの有無で試して比較してみた
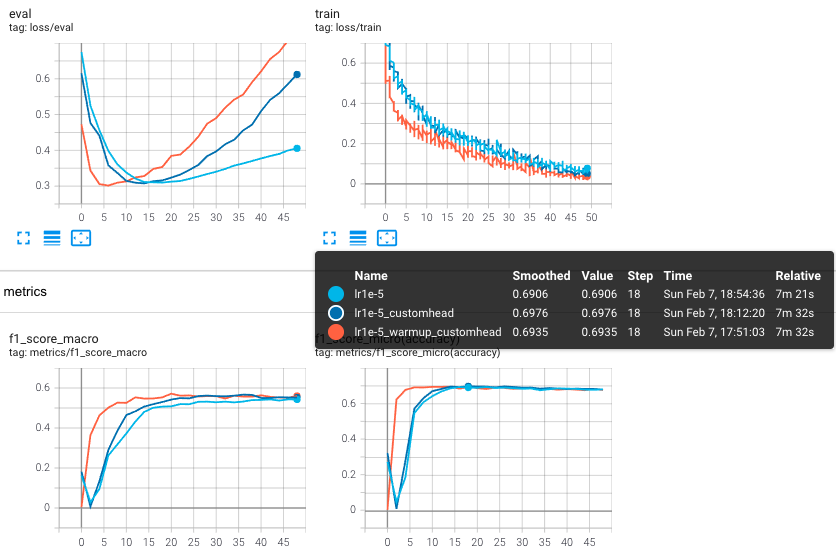
最終的に精度が飽和する部分の値はどれも同程度。最大値となる部分を比べると元のheadを使う場合は若干低い値となっている。スコアの立ち上がりはwarmupを使う場合が明らかに早いため、学習に時間がかかるものの場合は特に重要そう。ただ、custom headを使った場合のスコアはwarmupの有無で多少異なり、warmupのあり/なしでそれぞれ0.6950, 0.6976だった(誤差の範囲かもしれないが)
論文との比較ということで5 epochだけ学習させた場合のスコアがこちら(custom headかつwarmupあり)
- f1 micro: 0.673
- f1 macro: 0.464
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | micro avg | macro avg | weighted avg | samples avg | |-----------|----------|---------|----------|---------|----------|---------|----------|---------|---------|---------|---------|-------------|-------------|----------------|---------------| | precision | 0.785 | 0.000 | 0.722 | 0.849 | 0.854 | 0.699 | 0.698 | 0.453 | 0.781 | 0.000 | 0.000 | 0.760 | 0.531 | 0.683 | 0.723 | | recall | 0.779 | 0.000 | 0.781 | 0.497 | 0.794 | 0.453 | 0.791 | 0.192 | 0.592 | 0.000 | 0.000 | 0.620 | 0.444 | 0.620 | 0.639 | | f1-score | 0.782 | 0.000 | 0.750 | 0.627 | 0.823 | 0.550 | 0.742 | 0.270 | 0.673 | 0.000 | 0.000 | 0.683 | 0.474 | 0.642 | 0.648 | | support | 1101.000 | 425.000 | 1099.000 | 485.000 | 1442.000 | 516.000 | 1143.000 | 375.000 | 960.000 | 170.000 | 153.000 | 7869.000 | 7869.000 | 7869.000 | 7869.000 |
論文で書かれたスコアはこちら


microスコアは論文より若干低い程度だが、macroスコアが論文と比べて大きく下がっている。macroはラベル毎のスコアを出してから単純に平均を取るだけなので、ラベル毎のデータ数の差を考慮せずに等しく扱って平均を取っている。つまりデータ数が少ないことによってスコアが低いラベルがあればそれに引きづられて低いスコアになりやすい。
ラベル毎のスコアを見ると一目瞭然で、今回学習したものはデータ数が少ないラベル3種類で0%という結果になっている。これはさすがに何かおかしい気がするものの、データ数の多いラベルに引きづられてそちらを出力してしまったのかもしれない。
参考
- https://arxiv.org/abs/1812.01207
- https://qiita.com/koshian2/items/ab5e0c68a257585d7c6f
- https://yaakublog.com/crossentropy_binarycrossentropy
- https://scikit-learn.org/stable/modules/generated/sklearn.metrics.multilabel_confusion_matrix.html
- https://stackoverflow.com/questions/62722416/plot-confusion-matrix-for-multilabel-classifcation-python
- https://qiita.com/koshian2/items/c3e37f026e8db0c5a398
日本語のテキスト感情分類をやってみる
感情分類は以下の2通りに大分けされる模様
- positive/negativeの二値分類(neutralを含める場合もあり)
- joy, sadnessなど複数の感情に分類
このうち特に2.についてはapiとして公開されているものもそこまで多くない印象なのでこちらについてやってみることにした
簡単に論文を調べてみると、やはり感情分類も大規模な事前学習済みモデルに対してfinetuneするのがよさそう
https://arxiv.org/abs/1812.01207
↑の概要としては
- amazon reviewのテキスト40GBで事前学習(transfomerやLSTMなど複数モデル)
- semeval2018やcompany tweetsなどいくつかのデータセットでfinetune
- データセット毎にパフォーマンス比較しtransformerが良い結果
- apiとして公開されているWatsonよりも大幅に良い
ということで同じ方向でやる。ただし、事前学習を自前でやるのはコストがかかりすぎるためpublicに上がっているbertの日本語学習済みモデルを利用する
(ニュースやwikiなどに比べてamazon reviewは感情を多めに含むため感情分類の事前学習として効果が高い、と書かれているがさすがに日本語のamazon review学習済みモデルなど見つからなかった)
データセット
英語であれば感情分類用のデータセットがいくつかあるみたいだったため、今回はそれを日本語に翻訳して試してみることにした
できるだけ多くデータがあるものがよいと思い調べてみたが、こちらで複数のデータセットを集めてくれている方がいた
https://github.com/abishekarun/Text-Emotion-Classification
この中でequity evaluation corpusは同じ文の細かい部分を変えただけのものが大量に並んでいるものだったため除外し、text_emotion.csvとtweets_clean.txtを使う(合わせて5万件程度になる)
前処理(ラベル統合)
まず学習に使うラベルを限定する こちらのようにした
data = pd.read_csv(args.input_path, sep='\t', encoding='utf-8', names=['text', 'label']) # 不必要なlabelを除外 data = data[data.label != 'neutral'] data = data[data.label != 'empty'] # labelをまとめる data.label = np.where(data.label == 'enthusiasm', 'joy', data.label) data.label = np.where(data.label == 'love', 'joy', data.label) data.label = np.where(data.label == 'fun', 'joy', data.label) data.label = np.where(data.label == 'relief', 'joy', data.label) data.label = np.where(data.label == 'happiness', 'joy', data.label) data.label = np.where(data.label == 'hate', 'disgust', data.label) data.label = np.where(data.label == 'worry', 'disgust', data.label) data.label = np.where(data.label == 'boredom', 'sadness', data.label) data.label = np.where(data.label == 'fear', 'surprise', data.label) data.to_csv(args.output_path, sep='\t', header=False, index=False)
最終的に使うラベルはanger, disgust, joy, sadness, surprisedの5つ
データ数が近くなるようにマージした方が学習としてはよいのだが、使うことを考えるとangerやsurprisedは入れておきたかったのでデータ数は少ないが残した
前処理(クリーニング)
こんな処理を入れた
#/bin/bash
src_path=$1
src_name=$(basename $src_path)
if [ $src_name == 'tweets_clean.txt' ]; then
cat $src_path \
| awk -F'\t' '{print($2, "\t", $3)}' \
# ラベルの頭に::が付いているため除去
# ダブルクォーテーションを除去
| sed -e 's/\t\s*::\s*/\t/' -e 's/"//g' \
# urlエンコードされている文字列を復元
| sed -e 's/</</g' -e 's/>/>/g' -e 's/&/\&/g' -e "s/"/'/g"
exit
fi
if [ $src_name == 'text_emotion.csv' ]; then
cat $src_path \
# ヘッダーを除く
| tail -n +2 \
# csvをtsvへ変換
| python3 -c 'import csv, sys; csv.writer(sys.stdout, dialect="excel-tab").writerows(csv.reader(sys.stdin))' \
# 制御文字とダブルクォーテーションを除去
| sed -e 's/^M//g' -e 's/"//g' \
# urlエンコードされている文字列を復元
| sed -e 's/</</g' -e 's/>/>/g' -e 's/&/\&/g' -e "s/"/'/g" \
| awk -F'\t' '{print $4"\t"$2}'
exit
fi
ファイル毎にフォーマットが異なるのでそれぞれ処理した
翻訳
google翻訳よりも自然な日本語が出てくると思うのでDeepLで翻訳
こんな記事を書いてくれている方がいて大変助かりました
https://self-development.info/google%E7%BF%BB%E8%A8%B3%E3%82%88%E3%82%8A%E5%84%AA%E3%82%8C%E3%81%9Fdeepl%E7%BF%BB%E8%A8%B3%E3%81%A7%E8%87%AA%E5%8B%95%E7%BF%BB%E8%A8%B3%E3%80%90%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3/
サーバに負荷をかけないよう手作業と同程度ということで5秒に一回のペースでリクエスト
ちなみに、2000リクエスト程度投げた時点でしばらくレスポンスが返ってこなる。15分くらいするとまた返ってくるようになるが、再度2000リクエスト程度投げるとまた返ってこなる。すると今度は60分くらい経つと再びレスポンスが来るようになる。という感じで必要な待ち時間が徐々に長くなっていくので適当なところでプロセスを再実行する必要があった(再実行した場合はすぐに返ってくる)
実装
transformersを利用。文章の分類を行うためのクラスが用意されておりラベル数指定で簡単にheadを追加して分類の学習ができる https://huggingface.co/transformers/model_doc/bert.html#bertforsequenceclassification
また、東北大で作成されたbertの日本語学習済みモデルも利用可能
https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking
どうなっているのかの把握のため中を見てみる。Headはこちら
https://huggingface.co/transformers/modules/transformers/models/bart/modeling_bart.html#BartForSequenceClassification.forward
bertではなくbartのドキュメントを見てたことに気づいたため以下で書いたそのあたりの説明を修正しました
https://huggingface.co/transformers/modules/transformers/models/bert/modeling_bart.html#BartForSequenceClassification.forward
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
self.init_weights()
def forward(self, ...):
...
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
...
class BertPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
pooled_outputというのはBertの最終的な出力から最初のtokenの結果だけを抽出したもの(BertModelの最終層の出力をBertPoolerに通したもの)
headの処理としてはそれをdropoutにかけてから全結合層に通すだけのシンプルなものだった。
自分で書いた部分のコードでちょっと工夫した点として、高速化のためapexを入れてfp16対応している。以前書いた記事でやったのとまったく同じで簡単にできた
https://jsapachehtml.hatenablog.com/entry/2020/05/04/200757#fp16%E5%AF%BE%E5%BF%9C
ちなみに後から気づいたが、transformersにはTrainerの実装も用意されていたようでこれを使えばもっとスマートにできたはず
https://huggingface.co/transformers/main_classes/trainer.html
今度何かあれば使ってみる
今回実装したコードの全体はこちら
https://github.com/y-kamiya/emotion-classification/blob/c7d98b2/trainer.py
評価
学習部分は特別なことをしておらず簡単だったため、どちらかというと評価用の出力を出す部分で時間がかかった
どのラベルが他のラベルと間違いやすいのかという点を知りたいため評価時のログとtensorboardに混同行列を出力
from sklearn import metrics
import pycm
class EmotionDataset(Dataset):
label_index_map = {
'anger': 0,
'disgust': 1,
'joy': 2,
'sadness': 3,
'surprise': 4,
}
...(以下略)
def __log_confusion_matrix(self, all_preds, all_labels, epoch):
label_map = {value: key for key, value in EmotionDataset.label_index_map.items()}
# 混同行列を作成
cm = metrics.confusion_matrix(y_pred=all_preds.numpy(), y_true=all_labels.numpy(), normalize='true')
display = metrics.ConfusionMatrixDisplay(cm, display_labels=label_map.values())
display.plot(cmap=plt.cm.Blues)
# tensorboardへ出力
buf = io.BytesIO()
display.figure_.savefig(buf, format="png", dpi=180)
buf.seek(0)
img_arr = np.frombuffer(buf.getvalue(), dtype=np.uint8)
buf.close()
img = cv2.imdecode(img_arr, 1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
self.writer.add_image('confusion_maatrix', img, epoch, dataformats='HWC')
# コンソールログ用の混同行列
cm = pycm.ConfusionMatrix(actual_vector=all_labels.numpy(), predict_vector=all_preds.numpy())
cm.relabel(mapping=label_map)
cm.print_normalized_matrix()
こちらを参考に混同行列の画像をnumpy arrayとしてtensorboardへ出力
https://jun-networks.hatenablog.com/entry/2019/11/01/020536
また、コンソールログへの表示用としてpycmを使ってみた
https://blog.ikedaosushi.com/entry/2019/05/27/102818
各種スコアも出すためtabulateでpandasのDataFrameを出力した
columns = EmotionDataset.label_index_map.keys() df = pd.DataFrame(metrics.classification_report(all_labels, all_preds, output_dict=True)) print(tabulate(df, headers='keys', tablefmt="github", floatfmt='.2f'))
この際、colaboratory上で表の表示が崩れて見づらかったがブラウザのfont指定がおかしいためだった
https://jsapachehtml.hatenablog.com/entry/2020/12/31/152704?_ga=2.25166645.904288289.1610768063-1050067043.1602897991
実験
colaboratory上で実行
!python trainer.py --dataroot "$DATAROOT" --n_labels 5 --batch_size 96 --epochs 30 --fp16 --log_interval 120 --eval_interval 2 --lr 1e-5 --name lr1e-5 !python trainer.py --dataroot "$DATAROOT" --n_labels 5 --batch_size 96 --epochs 30 --fp16 --log_interval 120 --eval_interval 2 --lr 5e-6 --name lr5e-6
データセットは以下のようなフォーマットでtrain.txt, eval.txt(実際はtsvだが)として$DATAROOTで指定したディレクトリ直下に置いてある。
@tommcfly トム 準備してください ここポルトアレグレは本当に寒いです disgust ...
データ数は全体の10%程度を評価用に使ったので以下のよう
- train.txt: 46235
- eval.txt: 4962
結果がこちら

2 epoch実行した時点でf1 score(macro): 0.436が最大値。評価データへのlossもその後は上昇しており過学習しているといえる。
同じ時点での他の指標はこちら
Predict anger disgust joy sadness surprise Actual anger 0.16779 0.20805 0.21477 0.12752 0.28188 disgust 0.00498 0.39343 0.33964 0.18227 0.07968 joy 0.00143 0.09685 0.73998 0.06679 0.09494 sadness 0.00585 0.24122 0.27986 0.36885 0.10422 surprise 0.00815 0.13388 0.35623 0.08498 0.41676 | | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | accuracy | macro avg | weighted avg | |-----------|--------|---------|---------|--------|--------|------------|-------------|----------------| | precision | 0.56 | 0.42 | 0.63 | 0.43 | 0.47 | 0.53 | 0.50 | 0.52 | | recall | 0.17 | 0.39 | 0.74 | 0.37 | 0.42 | 0.53 | 0.42 | 0.53 | | f1-score | 0.26 | 0.40 | 0.68 | 0.40 | 0.44 | 0.53 | 0.44 | 0.52 | | support | 149.00 | 1004.00 | 2096.00 | 854.00 | 859.00 | 0.53 | 4962.00 | 4962.00 |
最後の表の中のaccuracyはf1-score(micro)と同等のもの。今回はラベル毎のデータ数に大きな違いがあるのでこちらで評価した方がよかったかもしれない。
ちなみにf1-score(micro)も上記に書いた2 epoch目が最大値だった。
tensorboardに上げた混同行列はこんな感じになって見やすい

やはりデータ数の多いjoyが特に精度高くなった。というより全体的にjoyである確率が高めになっており、これはデータ数的にjoyと答えておけば正答率が高くなるという学習の仕方になっているのかも。
ただ、anger以外については真のラベルに合致するものがちゃんと予測確率として最大にはなっているのである程度の学習はできていそう。最も少ないangerについては残念な結果。
実際にeval.txtで予測したデータを確認してみると以下のような感じだった
正解していたデータ
# 左から順に、予測ラベル/各ラベルの確率(%)/真のラベル/テキスト # 数字は表の並びと同じでanger, disgust, joy, sadness, surprised disgust [ 1. 59. 13. 23. 4.] disgust @tommcfly トム 準備してください ここポルトアレグレは本当に寒いです surprise [ 2. 6. 36. 3. 52.] surprise そう @palinoia 彼らはイスラエル人と外国人のために事実を隠蔽する言葉を使い、無知を利用して広め、支持を得ようとしている #zionism sadness [ 1. 24. 2. 72. 2.] sadness ティムがいないとプールが楽しくない... joy [9.e-02 2.e+00 1.e+02 9.e-01 2.e+00] joy メライとバデットと一緒にプーケットを楽しんでいます。 anger [79. 2. 5. 10. 4.] anger 土曜の夜、私は仕事のことで激怒している。 #paperproblems #isitchristmasyet
不正解だったデータ
# "いいライブ", "嬉しい"に引きづられていると思われる joy [ 1. 3. 53. 39. 5.] sadness いいライブだったよ(о´∀`о) 寂しくなるわ @eshshanane. NYCはあなたがいてくれてラッキーだよ。嬉しい #ジョイ #ポンズ # "悲しみ"に引きづられていると思われる sadness [ 6. 14. 6. 68. 6.] joy 悲しみは人生に必要な悪である。 # 確率的にほぼ同等で微妙(言い方によってはangerとも取れる文なので難しい文と言える) disgust [ 2. 34. 15. 18. 32.] sadness @SaschaIllyvich 私の話をベータ版で読んでないってことかな?
不正解だったが真ラベルがおかしそうなデータ
# 言われてイライラするならangerが正しそう anger [86. 3. 2. 5. 3.] surprise ミドルネームを言われると イライラするの ママが怒るとそう呼ぶの # これでjoyが真ラベルとはどういうことかw surprise [ 2. 5. 23. 3. 67.] joy 私が一日中履いていたパンツが透けて見えることが判明しました。 # 明らかにsadnessな感じ sadness [ 1. 13. 18. 64. 4.] joy 世界中のお金があっても、息子のいる専業主婦ほど幸せにはなれません。
ざっと見ていくと以下のような傾向が見て取れる
- わかりやすい単語が入っている場合はそれによって判定している
- 嬉しい、悲しい、怒りとか
- 真のラベルとして複数の感情が取れそうなものがある
- 特にdisgustとsadness(嫌だし悲しい)
- 前後の文脈や言い方次第で真ラベルが変わるものがある
- そもそも真ラベルが間違ってそうなものが意外とある
- (ラベル数を減らすためにいくつかをマージしたので当たり前だが)
真ラベルと比較すると不正解だが、上記のような難しい文やそもそもおかしい文がけっこうあるので、一個ずつ見ていくとそれなりに合っているように見えるもの多い印象
まとめ
既存のデータセットを翻訳して使い、目視でのクリーニングなどもしないという比較的手抜きな方法だが、その割にはまあまあの精度になったと思われる。間違っているもののそうとも取れるみたいな文が結構あったので、実際に予測に使うとf1-scoreの割にはあってるように見える予測ができそう。
次は以下をやってみる(かもしれない)
- マルチラベル分類にする
- データのクリーニングをもっとちゃんとやる
- 少なくとも翻訳ミスで英語のままになっている文など明らかなものは排除すべき
- ラベル毎のデータ数のバランスをとる
- 評価用のデータとして目視で真ラベルをチェックしてデータセットを作ってみる
- 分類器の部分に隠れ層を増やすとどうなる?
- 学習済みモデルのパラメータはフリーズして学習したらどうなる?
参考
- https://github.com/abishekarun/Text-Emotion-Classification
- https://huggingface.co/transformers/model_doc/bert.html
- https://self-development.info/google%E7%BF%BB%E8%A8%B3%E3%82%88%E3%82%8A%E5%84%AA%E3%82%8C%E3%81%9Fdeepl%E7%BF%BB%E8%A8%B3%E3%81%A7%E8%87%AA%E5%8B%95%E7%BF%BB%E8%A8%B3%E3%80%90%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3/
- https://paperswithcode.com/paper/practical-text-classification-with-large-pre
- https://tlkh.github.io/text-emotion-classification/
- https://note.nkmk.me/python-sklearn-confusion-matrix-score/
- https://blog.ikedaosushi.com/entry/2019/05/27/102818
- https://gotutiyan.hatenablog.com/entry/2020/09/09/111840
- https://jun-networks.hatenablog.com/entry/2019/11/01/020536